Subjects in contact interactions
- TRAIN set: 3 pairs of subjects
- TEST set: 2 pairs of subjects
In each recording, one subject is motion tracked with a marker-based motion capture system (Vicon). This motion is very accurate and is currently released. The second person is tracked using only RGB cameras.
|
 |
Multiple cameras
- 4 different views
- 900x900 resolution
- 50 fps
- Camera parameters:
- extrinsics
- intrinsics for 2 different camera models (one assuming image distortion, one ignoring it)
- The TEST set consists of only one random camera viewpoint per interaction scenario, to avoid simplifying the 3D Reconstruction challenge through multi-view triangulation/optimization.
|
 |
Various actions in various scenarios
Each pair of subjects performs the following actions under multiple interaction scenarios:
- Grab (20 interactions)
- Handshake (11 interactions)
- Hit (27 interactions)
- Holding Hands (7 interactions)
- Hug (10 interactions)
- Kick (19 interactions)
- Posing (8 interactions)
- Push (25 interactions)
|
 |
GHUM and SMPLX meshes
- Person 1: ground-truth, well-alligned mesh - obtained by fitting the GHUM model to accurate 3d markers, multi-view image evidence and body scans
- Person 2: pseudo-ground-truth mesh - obtained by fitting the GHUM model to multi-view image evidence and body scans
- We retarget the GHUM meshes to the SMPLX topology and provide pose and shape parameters for both
- 50 fps
|
 |
3D skeletons
25 joints (including the 17 Human3.6m joints)
- Person 1: ground-truth 3d skeletons
- Person 2: pseudo-ground-truth 3d skeletons regressed from the GHUM meshes
- 50fps
|
 |
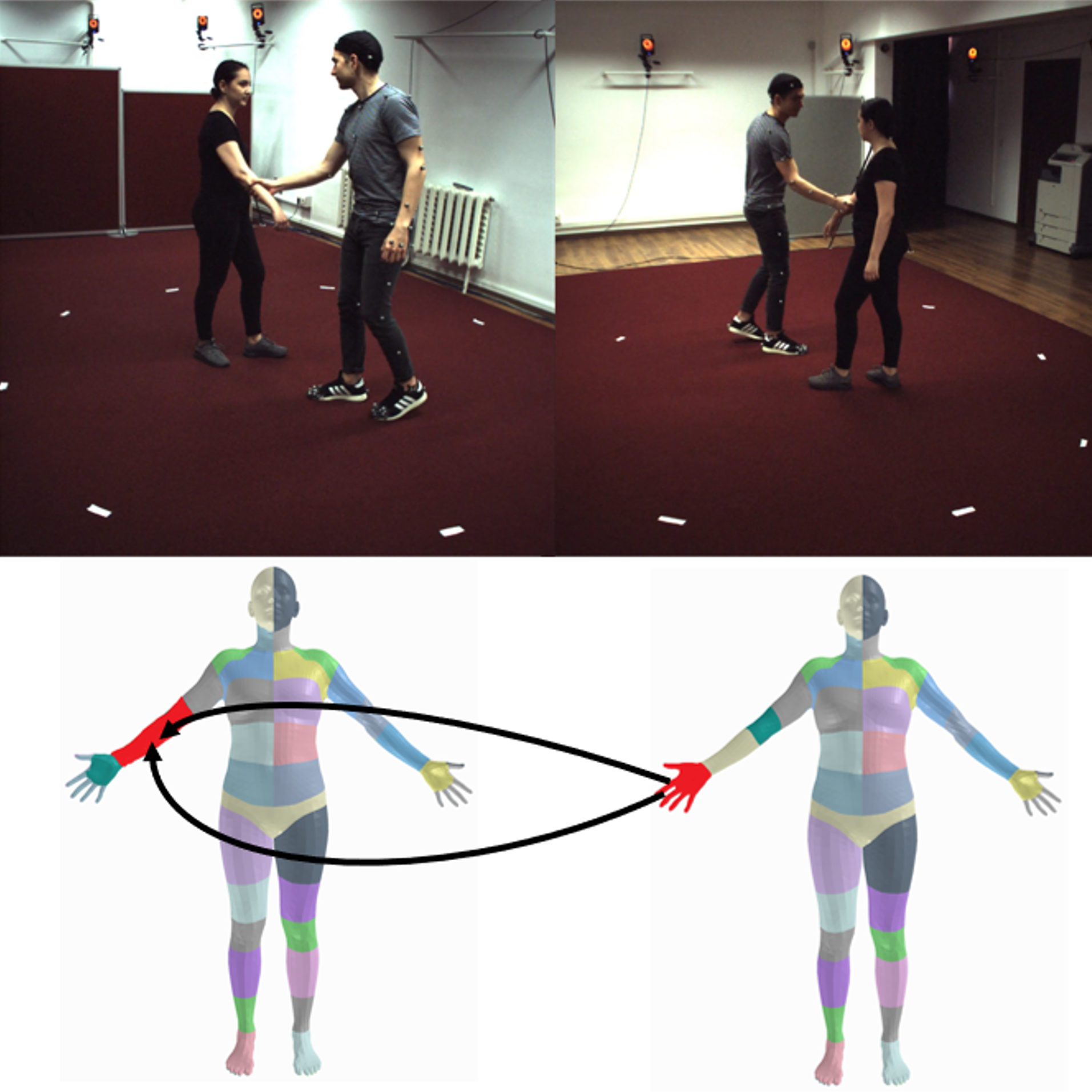
Contact signature annotations
Each of the 631 interaction recordings contain:
- 1 video timestamp where contact is established and the signature is annotated
- 1 contact signature annotation (multiple surface correspondences: triangle ids, vertex ids, region ids)
- timestamps of the start and the end of the contact
Due to the 4 viewpoints, this amounts to 2524 pairs of images and contact signatures.
|
 |
